February 19, 2026
*for some cases. Jane Street has an open source s-expression parser written in OCaml with an existing test suite as well as parser equivalence checks. I wanted to toss the problem of developing a more performant and memory efficient parser in OCaml at an agent harness and see what comes from it.
The results speak for themselves: all 7 original benchmarks won in both speed and memory (up to 3.07× faster, up to 5.75× less memory), plus the test agent generated 370 new test cases. You can view the Phase 3 test results for details.
If you’re interested in cloud sandboxes to run agents and code in, feel free to check out Vers or reach out if you have questions!
Contents
Phase 1
After being given the original code and existing test suite, I asked the agent to create a parser that’s more performant than the existing one and to include benchmarks for measurable scores. It made benchmarks for performance and memory with a few of the categories being actually more performant than the original parser. All being done in exactly 69 steps.
However, it wasn’t instructed to thoroughly beat all the benchmarks which resulted in an upsetting outcome.
Phase 2
Using the minimum context (tests and parser equivalence checks but no underlying logic), a new session was created with the explicit instruction of beating all the benchmarks in terms of performance and memory.
This was a success but contained a few correctness issues (ie specific character sequences or atoms that aren’t covered by the test suite).
Phase 3
The prior phases reveal two key things:
- A coding agent can be fired off and work till a test suite is fulfilled
- A single agent can write more performant Ocaml code than Jane Street
Which resulted in the third phase of this project where: a swarm is spun up with a subordinate to make a parser which beats benchmarks while passing tests, a subordinate to make more tests for strings that aren’t currently covered, and a subordinate to make additional ‘benchmarks’ to compare against the original parser.
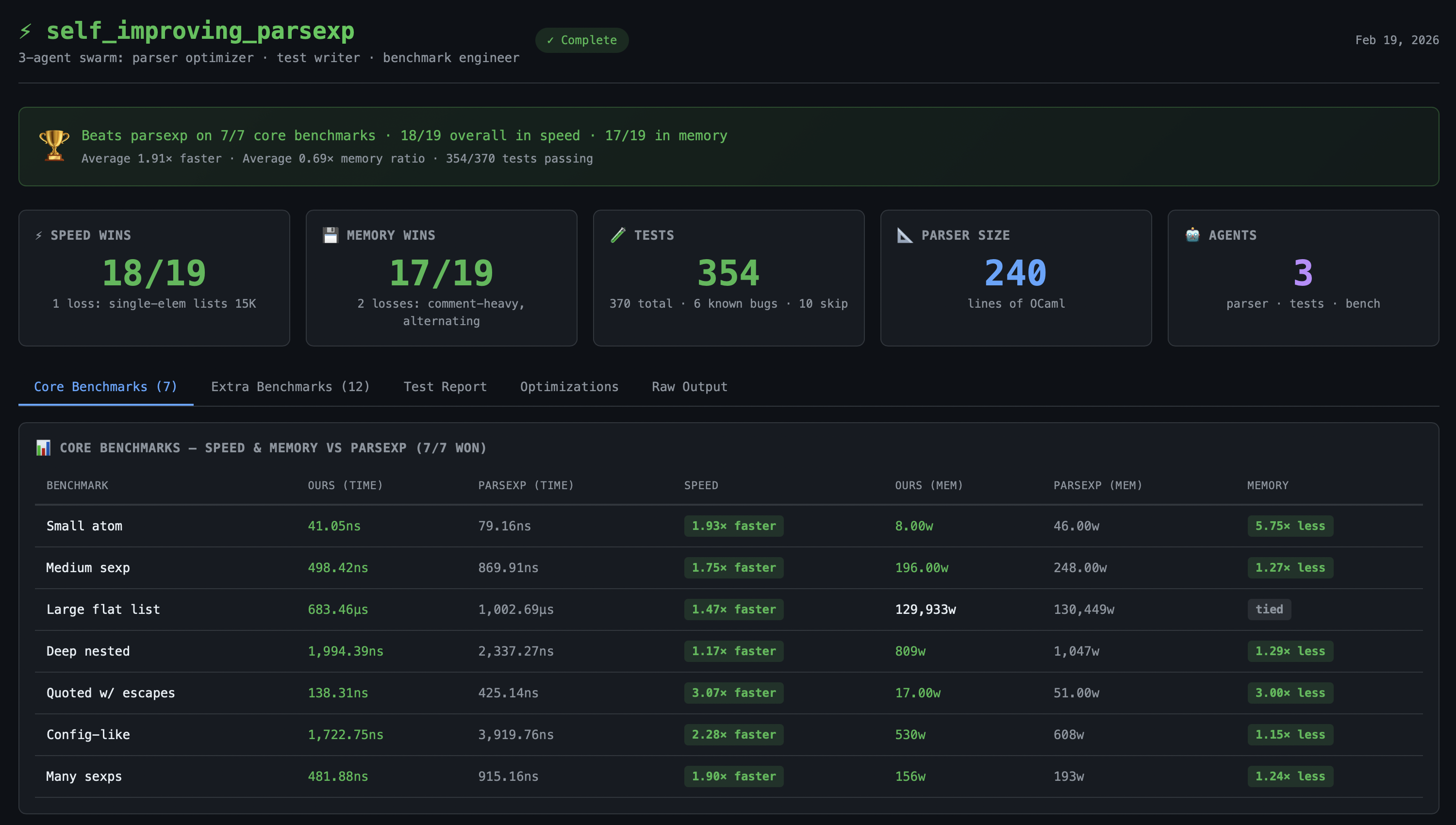
With a self-improving setup (where the resulting codebase is richer in coverage/validation), the latest parser has some trade-offs between the second iteration which are covered here. And all benchmarks are locally runnable following these instructions.
Source Code
It’s been linked a few times throughout this post but if you’re looking for this: https://github.com/hdresearch/parsexp